PDF는 보편적인 호환성과 문서 무결성 유지 기능으로 인해 광범위한 디지털 문서 영역에서 널리 사용됩니다. 그럼에도 불구하고 스캔한 PDF나 이미지 기반 PDF에서 텍스트를 추출하는 작업은 매우 복잡할 수 있습니다. 다행히 올바른 소프트웨어와 절차를 사용하면 품질 저하 없이 PDF 이미지를 텍스트로 빠르게 변환할 수 있습니다.
사진에 숨겨진 텍스트에 액세스할 수 있는 프로그램입니다. 이를 통해 다른 상황에서 PDF 이미지를 편집, 검색 및 재사용할 수 있습니다. 이 문서에서는 PDF 이미지에서 텍스트를 추출하는 방법과 기타 유용한 지침을 자세히 다루고 있습니다.
접근성과 사용 편의성으로 인해 많은 오프라인 소프트웨어 앱은 PDF 이미지를 텍스트로 변환하는 데 탁월합니다. 작업의 기밀을 보호해야 하거나, 변환 프로세스에 대한 완전한 명령을 가지고 있거나, 인터넷에 액세스할 수 없는 상황에서는 오프라인 도구가 유용합니다. 이미지 PDF에서 텍스트를 추출하는 몇 가지 훌륭한 오프라인 방법은 다음과 같습니다.
PDFelement는 스캔한 문서를 가져오고 PDF 이미지를 Word 또는 TXT 파일로 내보내서 PDF 이미지 내의 텍스트를 변경할 수 있는 강력한 PDF 편집기입니다. 이를 통해 표준 텍스트 문서와 동일한 방식으로 편집이 용이해집니다.
PDF를 이미지로 변환하는 것 외에도 PDFelement는 PDF를 DOCX, PPTX, XLS, HTML, RTF 및 TXT와 같은 다양한 파일 형식으로 변환하는 것을 지원합니다. 사용 편의성은 이 제품을 정의하는 특징 중 하나입니다. PDFelement는 Mac OS X, Windows , iOS 및 Android 지원하는 크로스 플랫폼입니다.
PDFelement를 최고의 PDF 편집기로 만드는 몇 가지 주요 기능은 다음과 같습니다.
그렇다면 PDFelement를 사용하여 이미지 PDF를 텍스트로 어떻게 변환합니까?
01 PDFelement를 다운로드하고 실행하세요. 이미지 파일을 프로그램에 끌어서 엽니다.
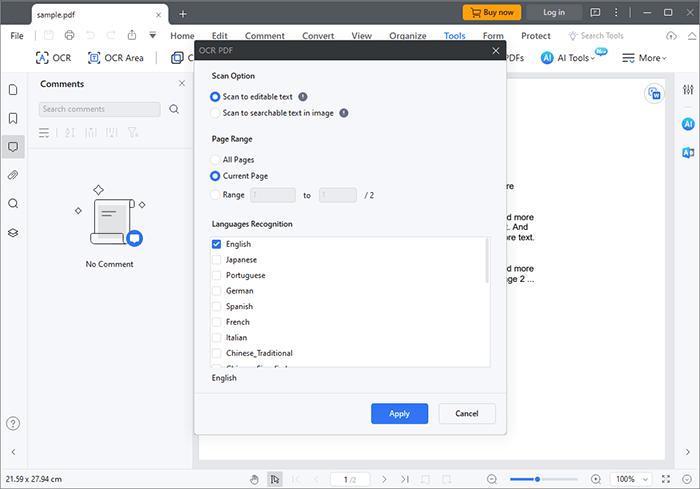
02 OCR을 활성화하려면 "도구"를 클릭하고 "OCR" 버튼을 탭하세요. "편집 가능한 텍스트로 스캔" 옵션을 선택하세요. 원하는 페이지와 언어를 선택한 다음 "적용"을 클릭하면 사진의 텍스트와 제목이 선택한 언어로 번역됩니다.
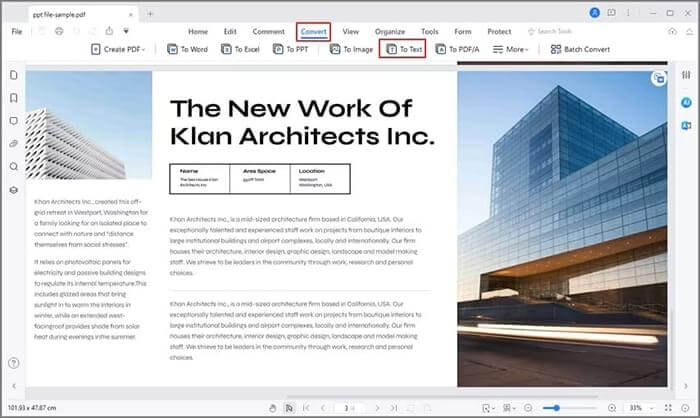
03 결과 홈 페이지에서 "변환" > "텍스트로"를 클릭하세요. 드롭다운 옵션에서 "TXT"를 선택하고 선택한 폴더에 파일 이름을 지정하고 저장한 다음 "확인"을 클릭합니다.
더 읽어보기: 이미지를 텍스트로 변환하기 위한 상위 5개 무료 OCR 소프트웨어
Windows 및 Mac 용 Adobe Acrobat을 사용하면 편집 및 검색 가능한 텍스트 문서를 얻기 위해 PDF를 다시 입력하거나 형식을 다시 지정하거나 다시 스캔할 필요가 없습니다. 원본 글꼴과 구조를 유지하면서 내장된 강력한 OCR 기능을 사용하여 스캔한 PDF를 텍스트 파일로 변환할 수 있습니다.
Adobe Acrobat을 사용하여 PDF 이미지에서 텍스트를 추출하려면 다음의 간단한 단계를 따르십시오.
1단계. Adobe Acrobat을 다운로드한 후 실행한 다음 OCR하려는 스캔 문서를 열고 "도구"를 선택합니다. "텍스트 인식"을 선택한 다음 "이 파일에서"를 선택하여 시작하세요.
2단계. 컨트롤을 사용하여 OCR을 조정할 수 있습니다. 텍스트 인식을 진행하려면, 번역하려는 문서가 시스템 기본 언어로 작성되어 있는 경우 "확인"을 선택하세요. "편집"을 클릭하고 "기본 OCR 언어" > "PDF 출력 스타일" > "다운샘플링 대상"을 선택합니다.
3단계. PDF 이미지를 오른쪽으로 설정하고 "서식과 함께 복사"를 선택합니다. PDF를 OCR하면 Acrobat은 인식된 텍스트를 원본 파일에 저장합니다. 그러나 이미지를 OCR하면 이미지가 텍스트와 함께 새 PDF 파일에 저장됩니다.
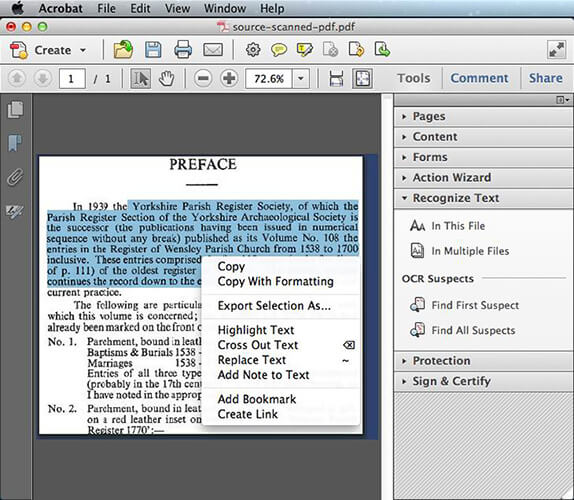
4단계. 선택 항목 내보내기 형식 탭으로 이동합니다. OCR 파일을 내보내려면 "다른 이름으로 저장"을 선택하고 파일 형식으로 "Word 문서"를 선택하세요. 새 파일의 위치를 선택하고 저장합니다.
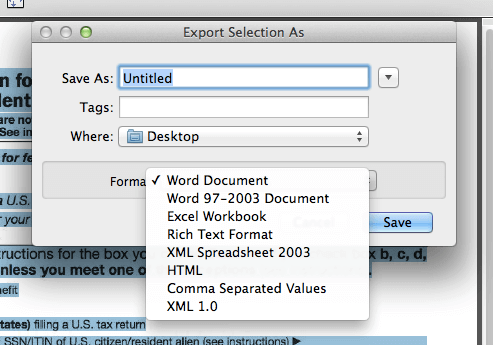
Soda PDF는 50개 이상의 PC 및 모바일용 PDF 애플리케이션 제품군으로, PDF 파일을 간단하게 변환, 보호, 생성 및 편집 할 수 있습니다. 내장된 OCR 기술은 이미지가 포함된 PDF를 편집 가능한 텍스트로 원활하게 변환할 수 있습니다.
Soda PDF를 사용하여 PDF 이미지에서 텍스트를 복사하는 방법을 알아보세요.
1단계. Soda PDF를 다운로드하고 실행합니다. 만들기 및 변환 모듈에서 "고급"을 선택한 다음 "PDF를 TXT로"를 선택합니다.
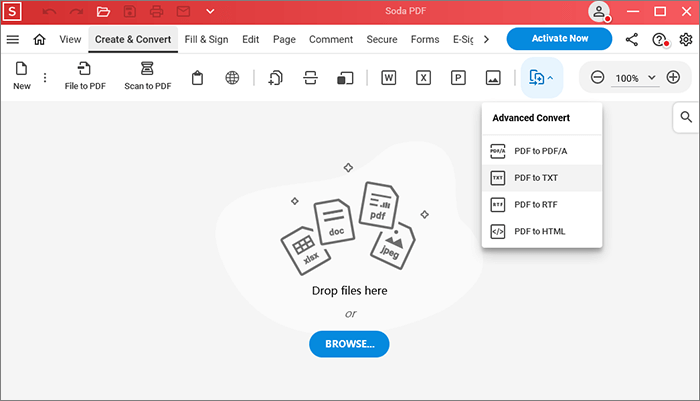
2단계. 변환이 필요한 페이지를 파악합니다. 추가 설정에 액세스하려면 세 개의 점을 선택하세요.
3단계. 기본 저장 위치를 변경하려면 폴더 아이콘을 클릭하세요. 스캔한 파일을 편집 가능하게 만들려면 OCR을 사용하세요. 그런 다음 "변환 후 TXT 문서 열기"를 선택하고 "내보내기"를 클릭하세요.
4단계. 파일 변환이 완료되자마자 이 알림을 받게 됩니다.
추천할 만한 것: PDF를 Word로 OCR 소프트웨어 검토: 정확성과 효율성 극대화
온라인 PDF 그림 텍스트 복사는 쉽고 효율적인 솔루션입니다. iLovePDF, PDF2Go, Online OCR 등과 같은 온라인 응용 프로그램 덕분에 추가 소프트웨어를 설치하지 않고도 PDF 사진을 텍스트로 변환할 수 있습니다. 다음은 온라인에서 PDF 이미지를 텍스트로 변환하는 데 유용한 몇 가지 방법입니다.
PDF2Go의 많은 인상적인 기능 중 하나는 이미지 PDF를 텍스트로 빠르고 쉽게 변환할 수 있는 OCR입니다. PDF2Go의 OCR 기능을 사용하면 주요 세부 정보를 쉽게 추출하고 편집 가능한 형식으로 문서를 열 수 있습니다.
PDF2Go를 사용하여 PDF 이미지를 텍스트로 변환하는 세 가지 간단한 단계는 다음과 같습니다.
1단계. PDF2Go 웹사이트에서 여기에 파일을 놓거나 "파일 선택"을 클릭합니다.
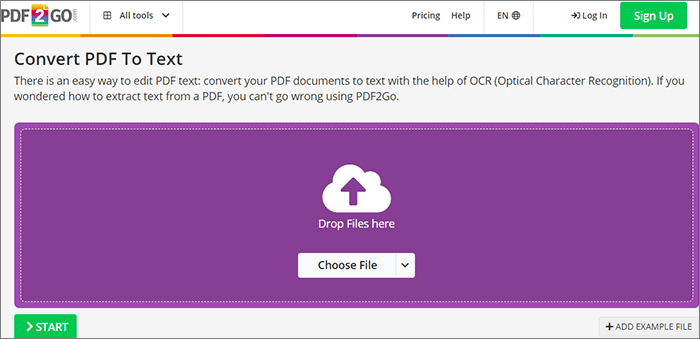
2단계. OCR로 변환하고 "START" 버튼을 탭하세요.
3단계. 변환된 파일을 다운로드합니다.
온라인 OCR을 사용하면 스캔한 PDF를 편집 가능한 텍스트로 쉽게 변환할 수 있습니다. 또한 원본 파일의 형식을 유지하면서 모든 이미지 파일 형식(JPG, BMP 또는 PNG)을 텍스트 출력 형식으로 변환할 수 있습니다. 온라인 OCR은 Windows , Mac OS 및 Linux와 호환됩니다.
온라인 OCR을 사용하여 PDF 그림을 텍스트로 변환하려면 아래의 간단한 절차를 따르십시오.
1단계. 온라인 OCR 페이지에서 "파일 선택"을 클릭하고 "ENGLISH" 언어를 선택하고 출력 형식을 "Text Plain"으로 선택합니다. 그런 다음 "변환" 버튼을 누르세요.
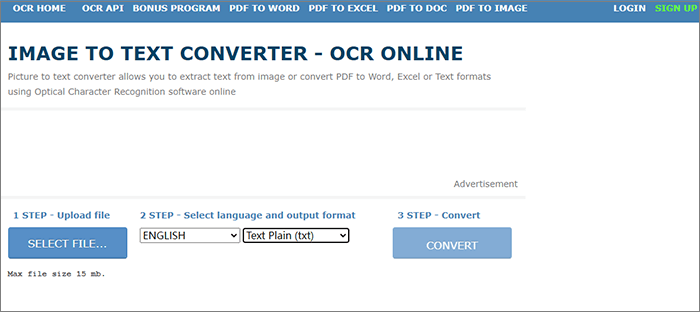
2단계. 출력 파일을 다운로드합니다.
참조: [종합 튜토리얼] PDF를 Word 문서로 저장하는 방법
OCR2EDIT는 사용자가 스캔한 PDF에서 텍스트를 읽을 수 있는 최첨단 프로그램입니다. 사용자 친화적인 인터페이스를 통해 스캔한 사진에서 텍스트를 빠르고 정확하게 가져올 수 있습니다.
OCR2EDIT를 사용하여 스캔한 PDF 이미지를 텍스트로 변환하는 방법에 대한 아래의 간단한 단계를 따르십시오.
1단계. OCR2EDIT 웹페이지를 열고 "파일 선택"을 탭하거나 여기에 파일을 놓습니다.
2단계. OCR 설정에서 필요에 따라 구성합니다. 그런 다음 "시작"을 클릭하십시오.
3단계. 변환된 파일을 다운로드합니다.
PDF 관련 작업을 위한 잘 알려진 온라인 플랫폼인 iLovePDF. 이미지에서 생성된 PDF를 편집 가능한 텍스트 파일로 변환하는 간단한 방법을 제공합니다. iLovePDF OCR 소프트웨어를 사용하면 스캔한 이미지와 그래픽 콘텐츠로 생성된 PDF의 텍스트에 액세스하고 작업할 수 있습니다. iLovePDF를 사용하여 스캔한 PDF 이미지를 텍스트로 변환하는 방법을 알아보려면 다음 3가지 주요 단계를 따르세요.
1단계. iLovePDF 웹사이트에서 "PDF 파일 선택"을 탭하거나 여기에 PDF를 놓습니다.
2단계. "OCR PDF"를 탭하세요.
3단계. 원하는 대로 선택하고 검색할 수 있는 PDF를 다운로드합니다.
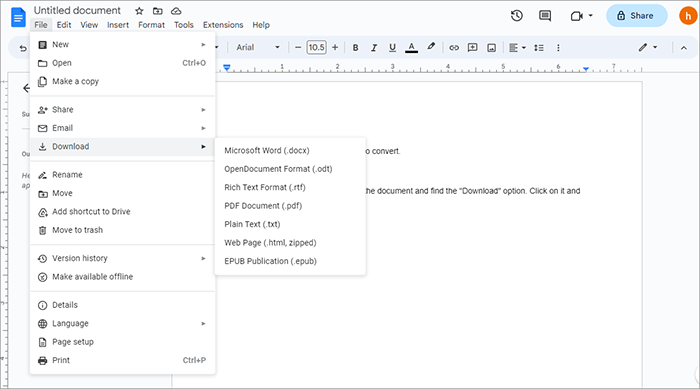
Google 문서도구는 사용자가 PDF, Word, 이미지 및 기타 형식을 열고, 읽고, 편집하고, 내보낼 수 있는 무료 온라인 서비스입니다. 스캔한 PDF와 이미지에도 OCR을 수행할 수 있습니다. 그러나 Google Docs의 OCR을 사용하는 경우 서식을 수동으로 수정해야 합니다. PDF에서 이미지와 텍스트를 추출하려면 아래의 간단한 절차를 따르십시오.
1단계. 내 드라이브 탭에서 Google 드라이브 에 파일을 업로드합니다.
2단계. PDF 이미지를 마우스 오른쪽 버튼으로 클릭하세요. "연결 프로그램" > "Google 문서도구"를 선택합니다.
3단계. 이제 Google Docs에서 파일 내용을 편집할 수 있습니다. "파일" > "다운로드" > "일반 텍스트(.txt)"를 클릭합니다.
PDF 이미지를 텍스트로 변환하는 방법을 아는 것은 문서의 접근성과 사용성을 높이는 데 유용합니다. 이 목적에 사용할 수 있는 다양한 대안 중에서 PDFelement를 활용하는 것이 좋습니다. 혁신적이고 간단한 OCR 기능으로 인해 다른 제품보다 돋보입니다. 이미지에서 정확한 PDF 텍스트 변환을 위해 지금 다운로드하세요.
관련 기사:
PDF를 Word에 쉽게 포함시키는 방법은 무엇입니까? [팁과 요령]




 PC용 무료 다운로드
PC용 무료 다운로드 Mac 용 무료 다운로드
Mac 용 무료 다운로드

