OCR(광학 문자 인식) 기술은 실제 문서에서 인쇄되거나 손으로 쓴 텍스트를 디지털화하여 편집 및 검색이 가능하도록 만드는 획기적인 기술입니다. PDF 파일에서 OCR을 제거한다는 것은 본질적으로 PDF의 텍스트를 다시 이미지로 변환하거나 단순히 인식된 텍스트 레이어를 제거하는 것을 의미합니다. PDF 파일에서 OCR을 제거하는 데 활용할 수 있는 다양한 방법이 있습니다.
이 기사에서는 PDF 파일에서 OCR을 제거하는 과정을 단계별로 안내합니다. 계속해서 읽으면서 PDF에서 OCR을 제거하는 방법을 알아보세요.
PDF 파일에서 OCR을 제거하려는 이유는 다음과 같습니다.
자세히 읽기: [해결됨] PDF 파일에서 권한을 쉽고 효율적으로 제거하는 방법
WPS는 MS Windows , Android , macOS, iOS , Linux 및 HarmonyOS용 오피스 제품군입니다. 가젯에 파일이 설치되어 있으면 이동 중에도 파일을 만들고 보는 데 도움이 될 수 있습니다. WPS 특수 기능을 사용하여 PDF 파일에서 OCR을 손쉽게 제거할 수도 있습니다. WPS Office를 사용하여 PDF에서 OCR 텍스트를 제거하는 방법은 다음과 같습니다.
1단계. 장치에 WPS가 설치되어 있는지 확인한 다음 WPS를 사용하여 PDF를 엽니다.
2단계. PDF를 연 후 상단 메뉴에서 "도구" 탭을 클릭하세요.
3단계. 도구 패널에서 "OCR"을 선택하면 OCR 설정 창이 열립니다.
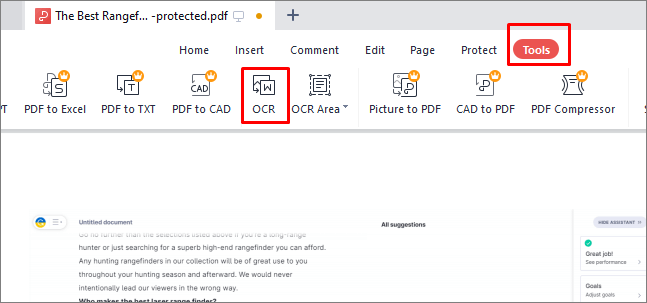
4단계. OCR 언어 드롭다운 메뉴에서 PDF에서 OCR을 제거하려면 OCR 언어를 "없음"으로 설정합니다.
5단계. "확인"을 클릭하여 설정을 저장합니다. 다음으로 "변환" 버튼을 눌러 OCR 없이 PDF 파일을 변환하세요.
6단계. 마지막으로 상단 메뉴에서 "파일" 버튼을 누른 다음 "다른 이름으로 저장"을 선택하고 그에 따라 새 PDF의 이름을 바꿉니다.
놓칠 수 없음: PDF 문서에서 배경을 손쉽게 제거 [사용 방법 튜토리얼]
Adobe Acrobat에는 PDF 생성 및 편집을 위한 다양한 기능이 제공됩니다. 이러한 기능 중 하나에는 PDF 파일에서 OCR을 제거하는 것이 포함됩니다. 데스크톱 애플리케이션으로 사용하거나 웹 브라우저를 통해 온라인으로 사용할 수 있습니다.
Adobe Acrobat을 사용하면 PDF 또는 스캔한 문서에 대해 OCR을 끄거나 제거할 수 있습니다. OCR은 기본적으로 켜져 있는 경향이 있습니다. 따라서 대부분의 경우 편집을 위해 PDF나 스캔한 문서를 열면 현재 페이지가 편집 가능한 텍스트로 변환됩니다. 다행히 파일을 편집 가능한 텍스트로 변환할지 여부에 따라 자동 OCR 옵션을 제거하거나 끄거나 켤 수 있습니다. Adobe Acrobat을 사용하여 PDF 파일에서 자동 OCR을 제거하는 방법은 다음과 같습니다.
1단계. 컴퓨터에 Adobe Acrobat이 설치되어 있는지 확인하세요. 앱을 실행한 다음 "도구"로 이동한 다음 "PDF 편집"을 클릭하세요.
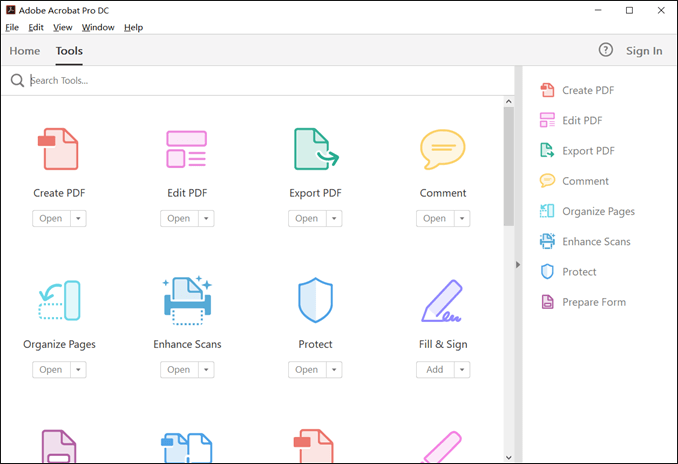
2단계. OCR을 제거하거나 끄려면 오른쪽 창으로 이동한 다음 텍스트 인식 확인란을 선택 취소하세요. 이렇게 하면 Adobe는 PDF/스캔 문서에서 OCR을 자동으로 활성화하지 않습니다.
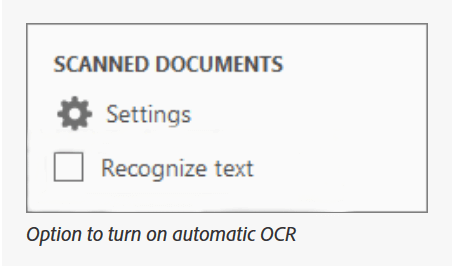
참고: OCR 출력이 검색 가능한 이미지 또는 검색 가능한 이미지와 정확히 일치하는 경우 Adobe Acrobat Pro를 사용하여 OCR을 제거할 수 있습니다. Adobe Acrobat X를 사용하는 경우 "도구" > "보호" > "숨겨진 정보"로 이동하세요. 숨겨진 정보 제거 창에서 "제거" 버튼을 클릭하세요. 숨겨진 텍스트 항목 옆에 체크 표시가 있으면 OCR 출력이 제거되었음을 의미합니다.
반면, Adobe Acrobat 8을 사용하는 경우 "문서"로 이동한 다음 "문서 검사"로 이동하세요. 문서 검사 대화 상자에서 "선택한 모든 항목 제거" 아이콘을 클릭합니다. 숨겨진 텍스트 항목을 선택하면 OCR 출력이 삭제된다는 의미입니다.
오래된 인쇄 문서, 손으로 쓴 편지, 중요한 정보가 포함된 스캔 이미지 등 어떤 것이든 편집 가능한 텍스트로 변환하면 시간과 노력을 절약할 수 있습니다. PDFelement는 이 작업을 효율적으로 수행하는 데 도움이 되는 다용도의 사용자 친화적인 소프트웨어 솔루션입니다. PDF에서 OCR을 직접 제거할 수는 없지만 PDFelement는 스캔한 문서나 이미지의 텍스트를 편집 가능한 텍스트로 변환할 수 있습니다.
스캔한 문서와 텍스트를 변환하는 것 외에도 PDFelement는 PDF에서 머리글 및 바닥글 제거 , PDF에서 텍스트 제거, PDF에서 채울 수 있는 필드 제거 또는 PDF에서 워터마크 제거 등과 같은 여러 다른 PDF 편집 기능을 수행할 수 있습니다. 이 문서 변환기는 다음과 같은 경우에 적극 권장됩니다. 일괄 처리 기능입니다. 파일 품질을 손상시키지 않고 여러 PDF를 동시에 처리할 수 있습니다.
PDFelement의 놀라운 기능은 다음과 같습니다:
PDFelement를 사용하여 스캔한 문서나 이미지의 텍스트를 편집 가능한 텍스트로 변환하는 방법은 다음과 같습니다.
01 장치에 PDFelement를 다운로드, 설치 및 실행합니다. 편집할 PDF를 업로드하려면 "PDF 열기"를 클릭하세요.
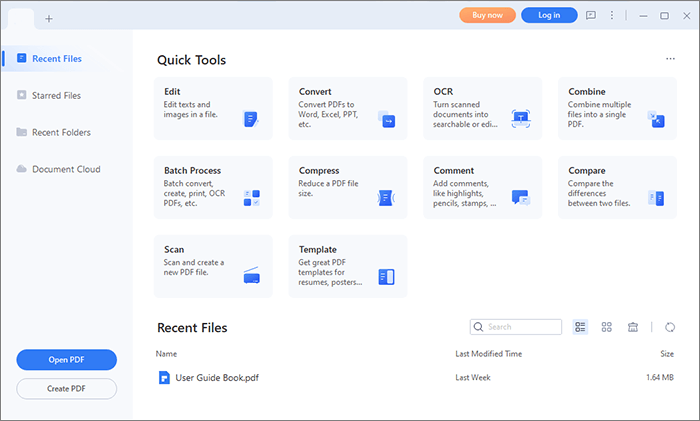
02 "도구" 버튼을 클릭하고 "OCR"을 선택하세요.
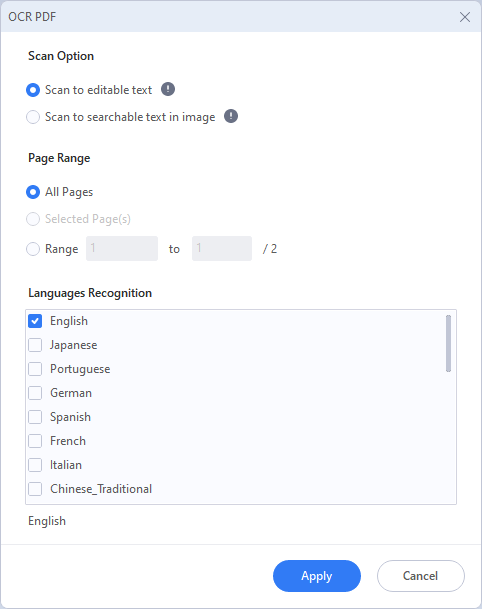
03 이때 팝업창이 뜹니다. "편집 가능한 텍스트로 스캔"을 선택한 다음 원하는 페이지 번호와 언어를 선택하고 "적용"을 클릭하세요.
04 프로세스가 완료되면 프로그램은 새로 생성된 편집 가능한 PDF 파일을 자동으로 엽니다. 일단 열리면 "편집" 버튼을 클릭하여 PDF 텍스트를 변경할 수 있습니다.
Q1: OCR 제거제를 사용하면 어떤 이점이 있나요?
강력한 OCR 제거제를 사용하면 다음과 같은 이점이 있습니다.
Q2: 온라인으로 PDF에서 OCR 레이어를 어떻게 제거합니까?
PDF에서 OCR 레이어를 제거하는 데 사용할 수 있는 몇 가지 수동 방법이 있습니다. 일반적인 것 중 하나는 PDF를 인쇄 하는 것입니다. Windows 의 기본 인쇄 기능은 아마도 텍스트 레이어를 제거합니다. PDF에서 OCR 레이어를 제거할 수 있는 또 다른 방법은 명령줄 유틸리티를 사용하는 것입니다. 즉, 스크립트를 작성하는 것입니다.
Q3: PDF에 OCR이 적용되었는지 어떻게 알 수 있나요?
PDF 파일을 열고 파일에서 단어를 검색할 수 있는지 또는 텍스트를 선택할 수 있는지 검색하세요. PDF에서 텍스트를 선택하거나 검색 할 수 없다면 스캔한 이미지일 수 있습니다. 반면, PDF에서 텍스트를 검색하거나 선택할 수 있다면 OCR이 적용되었을 가능성이 높습니다.
PDF 파일에서 OCR을 제거하는 것은 간단한 프로세스이며 향상된 문서 보안, 향상된 파일 품질, 다양한 장치 및 플랫폼에서의 향상된 호환성을 포함한 여러 가지 이점을 제공합니다. 이를 달성하려면 전용의 편리한 도구가 필요합니다. 여기에서 논의한 방법과 솔루션은 PDF 파일에서 OCR을 무료로 제거할 수 있는 옵션을 제공하며, 더 고급 기능을 원하는 사람들을 위해 프리미엄 대안도 제공됩니다.
그러나 스캔한 PDF 파일을 편집하거나 변환하려는 경우 PDFelement가 승리합니다. 다양한 기능을 갖춘 강력한 PDF 편집 소프트웨어입니다.
관련 기사:
최고의 PDF-Word 변환기 무료 오프라인: PDF를 Word로 쉽게 변환
[9 도구 리뷰] 가장 인기 있는 PDF-Word 변환기 온라인/오프라인




 PC용 무료 다운로드
PC용 무료 다운로드 Mac 용 무료 다운로드
Mac 용 무료 다운로드

